Modelli dei dati
I modelli costituiscono una strutturazione semplificata della realtà che ne accoglie aspetti specifici e aiuta a comprenderla meglio. Nell’ambito delle basi di dati, il modello dei dati rappresenta un insieme di strumenti concettuali, detto “formalismo”, che consta di tre componenti essenziali:
• Insieme di strutture dati, con operatori opportuni.
• Notazione per specificare i dati tramite le strutture dati del modello.
• Insieme di operazioni per manipolare i dati.
Qualsiasi modello dei dati deve risolvere due principali quesiti:
• Come rappresentare le entità e i loro attributi.
• Come rappresentare le associazioni.
Nel primo caso la maggioranza dei modelli usa strutture come i record, in cui ogni componente rappresenta un attributo. Nel secondo caso i modelli differiscono notevolmente nella ricerca di una rappresentazione, pertanto si possono proporre diversi esempi come le strutture, i valori, i puntatori ecc.
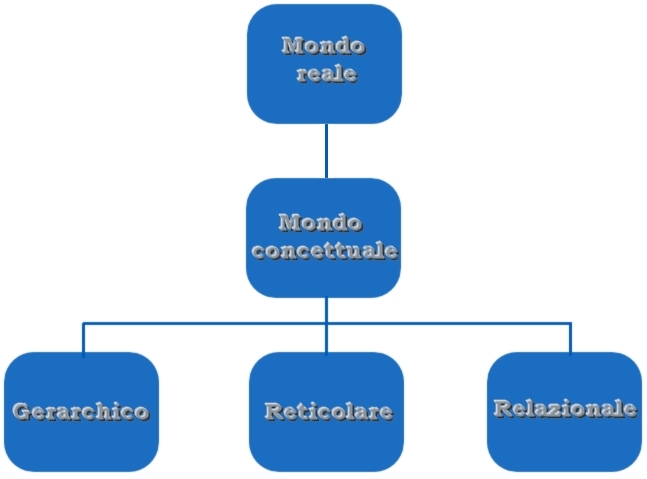
Cronologia dei modelli
Per la rappresentazione sono stati usati i modelli negli anni seguenti:
• gerarchico (anni ‘60)
• reticolare (anni ‘70)
• relazionale (anni ‘80)
• a oggetti (anni ‘90)
• Modello XML (anni 2000)
Modelli logici dei dati
Gerarchico
• i dati sono rappresentati come record
• le associazioni tra i dati sono rappresentate come puntatori in una struttura ad albero.
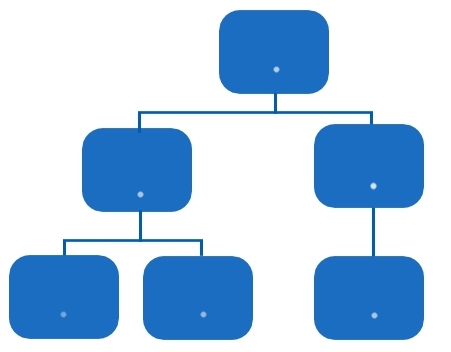 Modelli logici dei dati
Modelli logici dei dati
Reticolare
(CODASYL)
• i dati sono rappresentati come record
• le associazioni tra i dati sono rappresentate come puntatori in una struttura a grafo complesso
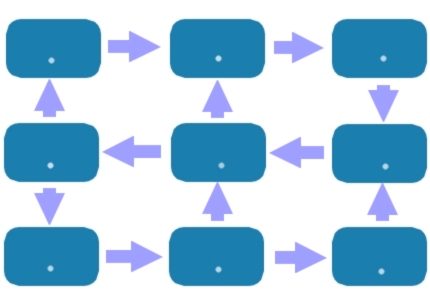
Modelli logici dei dati
Relazionale
• i dati sono rappresentati come tabelle
• le associazioni tra i dati sono ottenute associando valori di attributi in tabelle diverse
Cronologia del modello relazionale
• Inventato da T. Codd, 1970 (IBM Research di Santa Teresa, California.)
• Primi progetti:
– SYSTEM R (IBM), Ingres (Berkeley University.)
• Principali scoperte tecnologiche: 1978‐1980
• Primi sistemi commerciali:
– inizio anni ‘80 (Oracle, IBM‐SQL DS e DB2, Ingres, Informix,Sybase)
• Successo commerciale: dal 1985.
Definizione informale
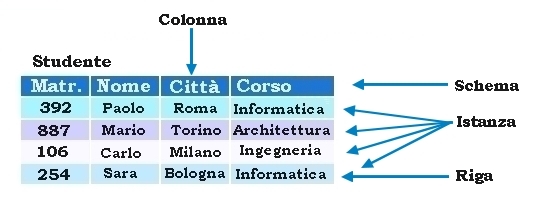
Tabelle e relazioni
• Una tabella rappresenta una relazione se
– i valori di ciascuna colonna sono fra loro omogenei (dallo stesso dominio)
– le righe sono diverse fra loro
– le intestazioni delle colonne sono diverse tra loro
• Inoltre, in una tabella che rappresenta una relazione
– l’ordinamento tra le righe è irrilevante
– l’ordinamento tra le colonne è irrilevante
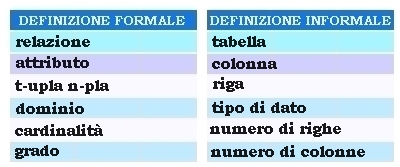
Confronto della terminologia
Il modello relazionale è basato su valori
• I riferimenti fra dati in relazioni diverse sono rappresentati per mezzo di valori dei domini che compaiono nelle ennuple.
Il modello relazionale è basato su valori
Perché sui valori?
• Indipendenza dalle strutture fisiche che possono cambiare anche dinamicamente
• Si rappresenta solo ciò che è rilevante dal punto di vista dell’applicazione (dell’utente)
• I dati sono portabili più facilmente da un sistema ad un altro
Riflessioni
• differenza fra schema e istanza
• due attivita’ assai differenti:
– progetto dello schema
– gestione dell’istanza
• passaggio dai dati all’informazione (Query language).
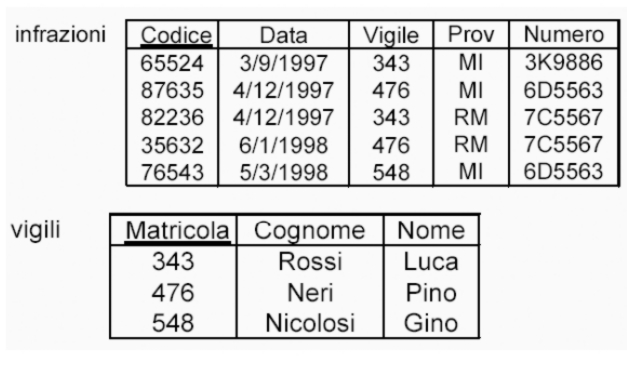
Un esempio due istanze di ricevuta fiscale.
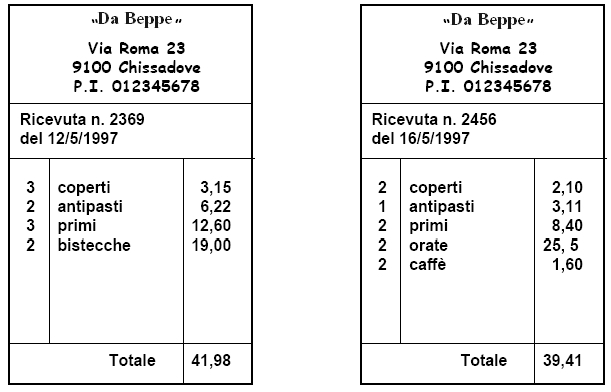
Rappresentazione Relazionale (1)
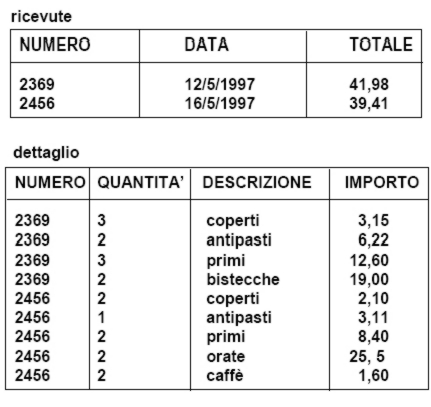 Rappresentazione Relazionale (2)
Rappresentazione Relazionale (2)
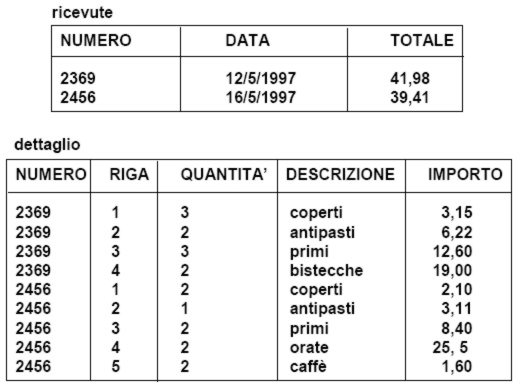 Informazione incompleta
Informazione incompleta
• ll modello relazionale impone ai dati una struttura rigida:
– le informazioni sono rappresentate per mezzo di ennuple
– solo alcuni formati di ennuple sono ammessi: quelli che corrispondono agli schemi di relazione
• I dati disponibili possono non corrispondere esattamente al formato previsto, per varie ragioni.
Informazione incompleta
 • Firenze è provincia ma non conosciamo l’indirizzo della prefettura
• Firenze è provincia ma non conosciamo l’indirizzo della prefettura
• Tivoli non è provincia: non ha prefettura
• Prato è “nuova” provincia: ha la prefettura?
Informazione incompleta
• Non conviene (anche se spesso si fa) utilizzare valori ordinari del dominio (0, stringa nulla, “99”, etc), per vari motivi:
– potrebbero non esistere valori “non utilizzati”
– valori “non utilizzati” potrebbero diventare significativi in fase di utilizzo (ad esempio, nei programmi)
• Risulta necessario ogni volta tener conto del“significato” di questi valori
Informazione incompleta
• Si adotta una tecnica rudimentale ma efficace:
– valore nullo: denota l’assenza di un valore del dominio (e non è un valore del dominio)
• Si possono (e debbono) imporre restrizioni sulla presenza di valori nulli.
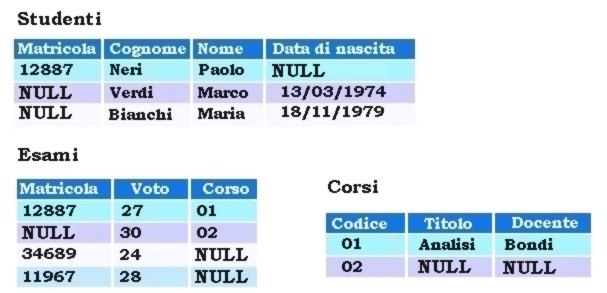
NULL
• Tre casi differenti
– 1) valore sconosciuto: esiste un valore del dominio, ma non è noto (Firenze)
– 2) valore inesistente: non esiste un valore del dominio (Tivoli)
– 3) valore senza informazione: non è noto se esista o meno unvalore del dominio (Prato)
• I DBMS e quindi non distinguono i tipi di valore nullo (implicitamente adottano il valore senza informazione)
Vincoli di integrità
• Escludono alcune istanze in quanto non rappresentano correttamente il mondo applicativo
– VINCOLI SUI VALORI NULLI
– INTEGRITA’ REFERENZIALE
– VINCOLI GENERICI
– CHIAVI
Vincoli di integrità
• Definizione:
– proprietà che deve essere soddisfatta dalle istanze che rappresentano informazioni corrette per l’applicazione
– ogni vincolo può essere visto come una funzione booleana (o un predicato) che associa ad ogni istanza il valore vero ofalso.
Vincoli di integrità
• Tipi di vincoli:
– intrarelazionali, casi particolari:
• su valori (o di dominio)
• vincoli di ennupla
– interrelazionali
• foreign key
Vincoli di dominio
• Risultano utili al fine di descrivere la realtà di interesse in modo più accurato di quanto le strutture permettano
• Forniscono un contributo verso la “qualità dei dati”
• Costituiscono uno strumento di ausilio alla progettazione (vedremo la “normalizzazione”)
• Sono utilizzati dal sistema nella scelta della strategia di esecuzione delle interrogazioni
• Non tutte le proprietà di interesse sono rappresentabili per mezzo di vincoli esprimibili direttamente
Vincoli di ennupla
• Esprimono condizioni sui valori di ciascuna ennupla, indipendentemente dalle altre ennuple.
• Una possibile sintassi: espressione booleana (con AND, OR e NOT) di atomi che confrontano valori di attributo o espressioni aritmetiche su di essi.
• Un vincolo di ennupla è un vincolo di dominio se coinvolge un solo attributo
• Esempi:
– (Voto >= 18) AND (Voto <= 30)
– (Voto =30) OR NOT (Lode = “e lode”)
– Lordo = (Ritenute + Netto)
Nozione di chiave
• Sottoinsieme degli attributi dello schema che ha la proprietà di unicità e minimalità
– unicità: non esistono due tuple con chiave uguale
– minimalità: sottraendo un qualunque attributo alla chiave si perde la proprietà di unicità
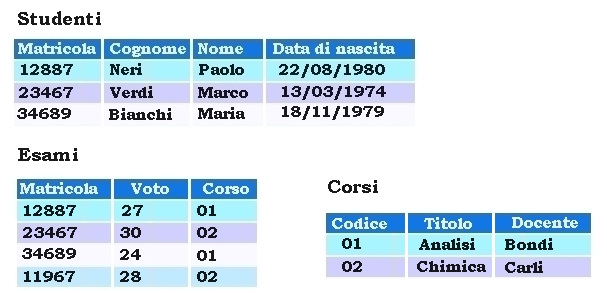
Chiavi nell’esempio : gestione degli esami universitari.

• Con molteplici chiavi:
– una e’ definita CHIAVE PRIMARIA
– le rimanenti chiavi sono SECONDARIE
CLIENTE: (COD_CLIENTE,INDIRIZZO, P_IVA)
• Chiave primaria:
– COD‐CLIENTE
• Chiave secondaria:
– P‐IVA
Importanza delle chiavi
• L’esistenza delle chiavi garantisce l’accessibilità a ciascun dato della base di dati
• Ogni singolo valore è univocamente accessibile tramite:
– nome della relazione
– valore della chiave
– nome dell’attributo
• Le chiavi sono lo strumento principale attraverso il quale vengono correlati i dati in relazioni diverse (“il modello relazionale è basato su valori”)
Chiavi e valori nulli
• In presenza di valori nulli, i valori degli attributi che formano la chiave
– non permettono di identificare le ennuple come desiderato
– né permettono di realizzare facilmente i riferimenti da altre relazioni
• La presenza di valori nulli nelle chiavi deve essere limitata
• Soluzione pratica: per ogni relazione scegliamo una chiave (la chiave primaria) su cui non ammettiamo valori nulli
Foreign Key
Una chiave esterna (ingl. foreign key) è un vincolo di integrità referenziale tra due o più tabelle. Essa identifica una o più colonne di una tabella (referenziante) che referenzia una o più colonne di un’altra tabella (referenziata).
I valori di un record delle colonne referenzianti devono essere presenti in un unico record della tabella referenziata. Ciò implica che un record nella tabella referenziante non può contenere valori che non esistono nella tabella referenziata (eccetto nel caso particolare di valori NULL). Più record della tabella referenziante possono puntare allo stesso record della tabella referenziata. Nella maggior parte dei casi, ciò corrisponde alla relazione “uno a molti” tra una tabella padre ed una tabella figlio.
Chiave ricorsiva
La tabella referenziante e quella referenziata possono essere la stessa tabella. Una chiave esterna di questo tipo è anche chiamata auto-referenziante o ricorsiva. Una tabella può avere molte chiavi esterne, ed ogni chiave esterna può referenziare una tabella diversa. Affinché sia rispettata l’integrità referenziale, ogni record di una query che sia stato dichiarato come foreign key può contenere solo valori della chiave primaria o chiave candidata di una tabella “madre” indentata. Per esempio, cancellare un record che contiene un valore a cui fa riferimento una chiave primaria di un’altra tabella violerebbe l’integrità referenziale. Alcuni RDBMS possono garantire l’integrità relazionale, o cancellando le rispettive colonne di foreign key, oppure fermando tutto e non effettuando la cancellazione. Spesso si può scegliere quale metodo usare attraverso una “diga” di integrità relazionale definito in un data dictionary.
• Informazioni in relazioni diverse sono correlate attraverso valori comuni
• In particolare, valori delle chiavi (primarie, di solito)
• Un vincolo di integrità referenziale fra un insieme di attributi X di una relazione R1 e un’altra relazione R2 impone ai valori su X di ciascuna ennupla dell’istanza di R1 di comparire come valori della chiave (primaria) dell’istanza di R2.
Foreign Key